
摘要
为帮助政策研究学者充分理解哪些文本挖掘工具能够进一步拓展经典理论问题的研究视野,对文本分析在政策研究领域的应用规律和发展趋势进行探讨。通过检索中外政策研究的重要学术期刊的相关文献,重点参考黄萃、吕立远的《文本分析方法在公共管理与公共政策研究中的应用》一文,通过“研究语料—研究逻辑”的类型学分析框架对文本分析在政策研究领域的研究方法应用进行研究综述,发现文本分析目前在“内容特征”和“描述性推论”方面应用更加广泛,进一步分析得出文本分析从描述性推论到因果推论、更多非结构化分析、从低频文本到高频文本信息、从单模分析到多源多模态数据分析的发展趋势。
引言
大数据时代社会科学的研究范式发生深刻变革,数据驱动的研究已经成为科学发展的重要趋势之一(Tansley and Tolle,2009)。得益于数字技术的发展和广泛应用,政策文献、社交媒体、法律文书、档案史料、网络信息等多样化的文本数据得以发掘,为研究者提供了更丰富的实证素材和更多元的研究视角。
政策研究及其相关领域已经广泛应用文本分析,在Web of Science 核心合集和CNKI数据库中CSSCI 和核心期刊中以“text analysis”(文本分析) 和“policy”(政策)检索得到相关中英文文献如图1,2015 年以后该方法已经在政策研究方法论体系中占有一席之地。
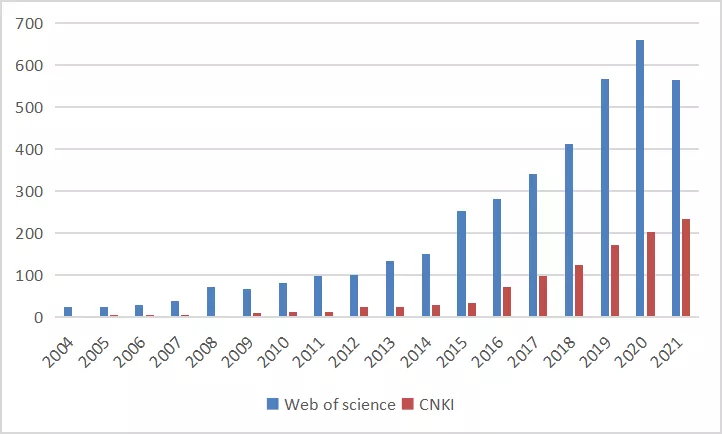
图1 文本分析的政策分析中英文文献发表趋势( 2004—2021年)
而很多研究仍停留在简单分类和观点提取层面,与大数据时代的社会科学发展要求不匹配。较多公共管理学者仍没有充分理解哪些文本挖掘工具能够进一步拓展经典理论问题的研究视野(Hollibaugh,2019)。因此,很有必要对文本分析在政策研究领域的应用规律和发展趋势进行探讨。
1.理论与方法
1.1文本分析
文本分析是指对文本的表示及其特征项的选取,以进行相应的文本挖掘、因果推断等数据分析。如表1,主要有六类常用的文本分析技术:
(1)主题分析(Thematic analysis):一般与扎根理论方法相结合,基于专家自身经验和对世界的理解,做出对数据的见解,从而构建新理论(Baumer, Mimno, Guha, Quan, & Gay, 2017);
(2)内容分析(content analysis)/基于词典的方法(Dictionary analysis):对文本单词/词组频率进行计数,以回答更多以定量为导向的研究问题(Reinard,2008;Short,Broberg,Cogliser&Brigham,2010;McKenny等,2016;Reinard,2008);
(3)词袋法(Bag-of-words):简化和压缩成为计算机容易理解的文档特征矩阵;
(4)监督学习(Supervise models):研究人员事先知道需要探寻数据x和标签y之间的关系(Roberts等,2014);
(5)无监督学习(Unsupervised models):通过事先定义的规则对文本数据进行自动分组(L. Jason Anastasopoulos,2019)。Karoliina Isoaho(2021)等认为主题建模使学者能够将政策理论和概念应用到更大的数据集上。
(6)自然语言处理(Natural Language Processing):文本分析中自动化程度最高的形式(Manning等,2008),模拟人类如何理解和处理语言(Chowdhury,2003;Collobert等,2011;Joshi,1991)。
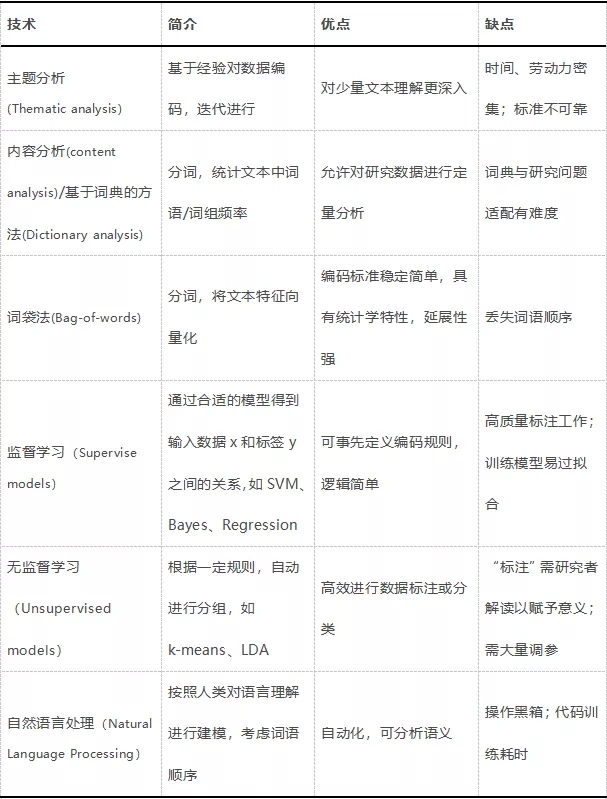
表1 文本分析主要技术简介
1.2 政策研究
政策研究是对政策的本质、特点、作用以及政策产生、发展、制订和实施规律的分析(周传虎,2019)。政策研究的目的是揭示政策制订和实施过程中固有的规律,提高政策的准确性和效益性,避免不应有的政策失误。
1.3 分析框架
为了把握文本分析在政策分析的主流方向,对中外政策研究领域较为顶级的期刊的相关研究进行重点关注。这些期刊包括管理世界、公共管理学报、金融研究、中国行政管理、情报学报 、中国工业经济 、数量经济技术经济研究、中国软科学、Administrative Science Quarterly、Public Administration Review、Research Policy、Journal of Public Administration: Research and Theory、Public Administration: An International Quarterly、American Economic Journal: Economic Policy、American Review of Public Administration 、Economic Policy、Environment and Planning C: Government and Policy、Environmental Science and Policy 、Governance: An International Journal of Policy,Administration and Institutions、Government Information Quarterly、International Review of Administrative Sciences 、Journal of Accounting and Public Policy、Journal of European、Public Policy、Journal of Policy Analysis and Management 、Journal of Social Policy。
采用基于“研究语料—研究逻辑”的类型学分析框架对文本分析在政策研究领域的研究方法应用进行研究综述,如图2。这一框架的构建有以下考虑: (1)方法论体系综述应当体现对于方法论核心要素的关注。“研究逻辑”和“研究语料”分别代表文本分析的研究目的和研究内容两个方法论体系中的核心问题。(2)该分析框架满足类型学研究“独立且穷尽”的基本原则( Minto,1996)。“研究逻辑”维度被划分为描述性推论和因果推论,“研究语料”维度被划分为形式特征和内容特征,理论上构成了所有文本分析研究的完备划分。(3)选择“研究逻辑”和“研究语料”两个维度进行分类,可以更好地呈现文本分析方法的发展趋势。
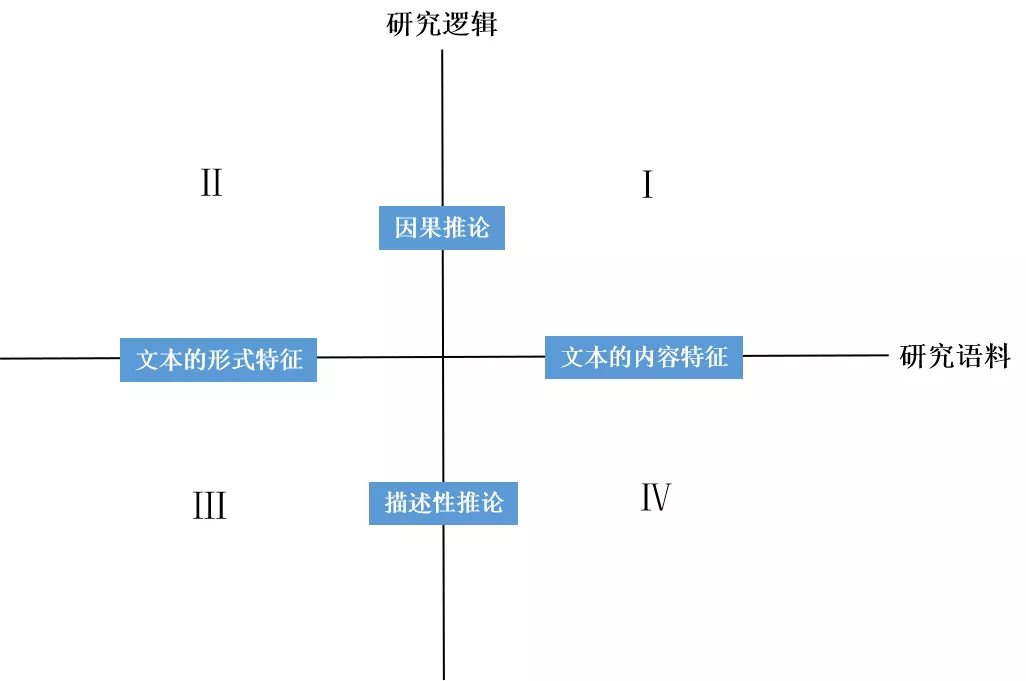
图2 研究分析框架
不同维度简要论述如下:
(一) “研究语料”维度: 文本的形式特征/内容特征
语料是经过科学抽样和处理生成的数字化文本,构建高质量的语料库是进一步挖掘文本隐含知识的基础和前提。选取“研究语料”作为分析框架的维度,分成文本的形式特征和内容特征,主要回答文本分析的研究素材。“研究语料”的形式特征,主要指文本的发布时间、发布主体等外在特征;“研究语料”的内容特征,主要指文本的词语搭配结构、句式结构和语义特征等内在特征。语料的形式特征与内容特征对研究者理解文本起到不同作用,文本内容特征可以帮助研究者更好地理解文本“生产者”微妙的情绪和态度变化,文本形式特征差异可以帮助研究者更好地在海量文本间进行比较,理解不同角色“生产者”的立场差异(黄萃,2016)。
(二) “研究逻辑”维度: 描述性推论/因果推论
“研究逻辑”是分析框架的另一维度,主要回答文本分析研究目的。“研究逻辑”维度分为描述性推论和因果推论。从方法论体系来看,推论是科学研究的基本目的,科学推论可以分为描述性推论和因果推论(King等,1994)。描述性推论侧重于利用观察值推理难以直接得出的结论,侧重于挖掘“是什么”。因果推论则更加深入,关注挖掘“为什么”,也更受到研究者关注。随着时间的推移,发展更加精确的因果推论已成为社会科学发展的重要趋势,文本分析作为一种新兴的社会研究方法也不例外。
2.文本分析在政策研究中的应用规律
由于文本形式特征的提取远远简单于内容特征,形式特征也成了数据时代文本分析的起点。本研究沿着由形式特征到内容特征、由描述性推论到因果推论的逻辑,对于文本分析在本领域中的应用场景进行综述。
2.1 基于形式特征在描述性文本分析
由于文本形式特征的提取远远简单于内容特征,形式特征也成了数据时代文本分析的起点。政策文本数据的结构化程度往往更高,其形式特征包括发文主体、发文时间、文件标题、文件主题词、文件参照关系等( 黄萃,2016)。一方面,可以通过政策文本形式特征对不同类型政策主体的特点、立场和行为规律进行时空比较。曾婧婧(2015)通过2004-2014 年233项泛珠三角区域合作政策文本,研究各子区域合作进程和政策工具的使用方面的特点。范梓腾等(2017)对2012年以来省级政府出台的大数据发展政策展开文献量化研究,通过内容分析从政策“目标-工具”匹配的视角分析地方政府大数据发展政策的主要内容、基本特征和发展趋势。吴芸等(2018)通过政策工具的强制程度、协同程度与整合程度分析京津冀区域大气污染治理政策工具的变迁。赵彦云等(2021)从政策实施时间、政策数量、政策相似度多个角度量化评价上网电价政策实施的地区差异。王芳等(2021)尝试分析政策发布时间、布局数量、政策主题强度、执行部门数量等多个维度,构建了一种基于多特征融合的政策扩散倾向性探测模型。
另一方面政策活动涉及政府、市场和社会等不同主体的互动,可形成错综复杂的网络关系。张国兴等(2019)基于1978年以来由国务院各部委颁布的 1493 条节能减排政策文本解释各部门在政策措施选择方面的差别及联系。张振华等(2020)从政策属性、政策目标、政策工具以及政策制定府际合作网络等方面对我国1978至2016 年制定的219条科技领域环境规制政策文本进行文献量化研究,以有效梳理科技领域环境规制政策变迁和府际合作的演进逻辑。
2.2 基于形式特征的因果性文本分析
形式特征往往更加离散化、形式特征往往具有较强的外生性使得利用形式特征开展因果性推断要更加困难。
一种兼顾实际意义和可操作性的研究路径是利用文本的形式特征,挖掘不同主体间相互合作、信息传递等社会互动关系,并解释这些互动关系的形成与演化规律。尚虎平等(2020)基于新中国70年来中央层面316份合作医疗政策文本,借助政策文本计量法探讨不同时期政策设计本身的工具性品质如何影响农村合作医疗参合率的变迁。Xiang, JQ等(2019)从政策文本提取政策发行机构之间的参考关系,获得政策扩散中的政府关系网络,实证研究得出知识产权政策的扩散与网络定位、权威、经济发展水平、政策及时性等许多制度因素呈正相关。
利用时间特征,研究者可以构建纵贯性的社会互动关系集合,从而更好地控制内生性,提供更高质量的因果推断环境。此时,研究者需引入动态网络动力学模型。例如,徐国冲和霍龙霞(2020)基于中央政府发布的 190 余份政策文本,构建了中央层面的食品安全监管合作网 络,并利用随机行动者导向模型(Stochastic Actor-Oriented Model)研究了2000—2017年中国食品安全监管网络演化的驱动因素,发现权威性逻辑是驱动网络演化的主要机制。总体来看,关注文本数据背后社会互动关系的形成机制尚属较为前沿的议题。
2.3 基于内容特征的描述性文本分析
内容特征是文本数据中非结构化程度较高的部分。与形式特征相比,文本的内容特征要更加复杂,话题、语气与遣词造句等诸多因素都可能直接导致文本的语义差异。这既给研究者带来了广阔的研究空间,也伴随着诸多挑战。
对于单一语义结构的倾向性研究,研究者经历了一个逐步深入的过程。早期的内容语义研究带有一定程度的文本解读色彩。研究者往往在确定先验规则的基础上,基于对规则的理解对文本进行主观编码,通过编码结果的统计分析挖掘文本的语义特征。一个典型案例是对于政策工具及其组合的研究。Dan等(2019)使用QDAMiner软件提取PDF和HTML政策文档的内容,通过对明确内容和潜在含义的推断提取政策文本特征,通过短语、句子和段落被用罗斯六个维度中的一个或多个编码来确定文本线性叙述,进行故事线分析表明苏格兰比加拿大的对吸毒更具惩罚性,对吸毒者的社会包容的方式更少。陈婧嫣等(2021)通过对全球科技强国人工智能政策文本的深度挖掘,分别从基于“目标-理念-路径”的静态视角和基于“学习-扩散”的动态视角出发,构建起人工智能领域的跨国比较分析框架。
随着数据规模的提升,基于先验规则的文本分析难以为继,面向大规模文本的自动信息提取研究逐步兴起。Driss OB等(2019)提供一个基于文本语义分析的通用框架,从社交媒体中提取有价值的数据,为政策制定提供新的信息。张维冲等(2020)研究了面向大规模政府公文的结构解析方法与信息抽取方法,为15种政府公文的语义结构解析提供了思路。
在对于主题内容进行定性判断的基础上,研究者还可以借助字典对文本进行定量的情感计算,从而建立起文本与理论概念间的连续映射关系,从而提升理论的概念化程度。Jiangnan Z等(2017)对2012年至2015年100只“大老虎”垮台的来自新浪、搜狐、腾讯、凤凰和财新网首次正式新闻报道后网民的37万多条在线评论进行词频分析、词云分析,表明公众对发起反腐运动的全国最高领导人的支持大大超过了对反腐机构和机构的支持。Shen Q等(2018)对中国大陆的一个主要语言政策倡议的媒体文本进行词频分析,考察了其他中文背景下的相关讨论,表明“资源”取向在捍卫大中华区语言政策制定的实施空间方面具有重要作用。Kim H等(2019)用韩国政策研究数据库,自动收集国家研究机构撰写的所有政策文章,通过概率主题模型提取10年来的潜在主题及其趋势,检测到的主题相当符合国家远见报告中专家选择的未来驱动因素,表明公共话语和政策议程是相结合的。Jacqueline C.K. Lam等(2019)基于240万个词的语料库,通过关键词分析、关键词共现、主题分析,对香港三个利益相关者群体(即政府(GOV)、环境组织(NGO)和新闻媒体(媒体)对空气污染政策的关注期刊进行比较,显示2002年至2012年间利益相关者的不同关注点,利益相关者主要关注排放和末端污染控制。Lh A等(2019)使用主题建模和视觉分析在“We the People ”请愿数据中发现的观点,提供对政策制定的可视化分析结果的可用性的评估。Wu Z等(2020)分析新浪微博用户的数据及其对强制城市固体废物(MSW)分类政策相关流行帖子的评论,探讨中国居民对MSW分类政策的情绪倾向,得出造成公众负面情绪的主要原因是罚款、MSW分类规则、费用、扔垃圾的时间和不规范的回收程序。
基于标注样本的有监督学习则相对少见,这很大程度上源于本领域高质量标注数据的稀缺。Tobback E等(2016)构建了一个用荷兰语表示的不确定性的模态项字典;用词袋法构建文本特征向量,使用支持向量机(SVM)对新闻文章进行分类,自动在文本文档中选择具有最大经济政策不确定性鉴别能力的单词。Loftis M等(2018)将人类编码与大型数据集的计算机自动分类相结合,提出基于贝叶斯模型的的自动文本分类算法,帮助研究人员从研究中获取更多信息。Liang D等(2021)设计基于两阶段的三向增强技术来自动政策文本段落分类到预定义的类别中。即在第一阶段,构建集成卷积神经网络(CNN)模型,根据准确度和分类可信度来综合所有基础分类器的预测结果,在三向决策(3WD)的帮助下,将分辨率较差的样本分配到边界区域进行二次分类。在第二阶段,利用传统的机器学习方法作为二级分类器。实验表明提出的方法可以有效地支持政策推荐平台的设计,以帮助中小企业更好地理解包容性政策。
对于多语义结构间关系的研究,研究者主要关注语义结构的相似性和关联性。研究者可以借助词嵌入等技术构建语义向量,通过不同向量间的距离来表征不同语义结构间的相似性,通过并列、转折、共现等特殊关系构建不同语义结构间的关系网络,从而挖掘出具有关联性的语义结构。Park C等(2017)通过对负责监督韩国能源政策的一个部的新闻稿进行潜在语义分析(LSA),并用余弦相似度测量语义距离,发现韩国能源总体规划(KEMP)中的核电政策与同期新闻稿的分析结果非常相似,进而通过对历史的新闻稿进行全面回顾,可以预测KEMP将提出的核政策。魏伟等(2018)根据工作报告中的关键词筛选提出社会活力的计算方法,并对特征词时间序列进行聚类分析,并结合特征词时间序列聚类结果进行特征词时间序列模式发现。Costa M(2018)研究公众评论与美国监管影响分析(RIAs)中使用的科学研究的文本相似度,以确定监管机构是否根据评论中引用的科学信息迭代地更新其监管规则,发现对于各种各样的评论者,国会成员和行业团体对RIAs中使用的研究的变化有最大的影响。Linder F等(2020)使用以相似顺序/序列对齐相似单词的算法,以识两项法案提出政策文本相似性,应用于500000张票据的语料库表明意识形态相似的发起人提出的法案显示出高度的文本重用。Sun Y等(2020)基于14995.5万篇微博文章和自然语言处理方法,分析了居民对电价政策情绪的时变特征、季节特征和机制。居民对电价政策表现出了积极的情绪,居民情绪的强度以三个阶段为特征,居民对政策的情绪有明显的季节差异。韩剑等(2021)构建亚太地区自由贸易协定(FTA)以全面与进步跨太平洋伙伴关系协定(CPTPP)为基准的协定相对深度指数,表明平均深度随着时间的推移缓增,并使用贸易协定之间的文本相似系数来比较各协定的相似性、差异性。
2.4 基于内容特征的因果性文本分析
随着提取复杂语义的技术日趋成熟,研究者开始将通过文本内容获取的复杂语义特征变量与因果推论相结合,更加深入地挖掘社会现象背后的因果关系。本质上,利用文本内容特征开展因果性分析并不是孤立的,而是在提取非结构化语义基础上的再发展。上述尝试大大拓展了文本分析研究者的研究视野,也是目前发展文本分析方法的前沿所在。
当利用文本分析进行因果推论时,研究者往往可以从两个维度出发。一是将文本作为“生产者”观点、特质与策略的反映。二是将文本作为“接受者”态度和行为的反映。Lauren等 (2017)研究表明关注气候导向行动的文本,可以减少恐惧和愤怒,有助于间接支持气候缓解政策,情绪对政策支持的影响取决于意识形态。Goldschlag等(2018)利用联邦法规代码的文本,统计每部分文本中限制性单词或短语的数量,创建按行业监管总量的年度度量,实证研究表明不断上升的联邦监管并不能解释经济活力的长期趋势。Senninger, R等(2020)利用欧盟委员会的网页上所有与政策相关的战略规划文件,用余弦相似度度量政策之间的重叠,通过实证研究表明部门间的协调主要是由对行政失误的关注所驱动的,从而为谈判协调的视角提供了支持。李晓溪等(2021)探究问询函前后并购报告书文本特征变量(标的方历史信息含量、标的方前瞻信息含量、的标的方历史信息的详细程度、信息披露指标)的变化,表明问询函制度通过改善信息披露缓解了并购交易的信息不对称问题。姜富伟等(2021)利用金融情感词典和文本分析技术,分析中国人民银行货币政策执行报告的文本情绪、文本相似度和文本可读性等多维文本信息,刻画央行货币政策执行报告的文本特征,探究货币政策报告的文本信息与宏观经济和股票市场的关系。
除此之外,要更好地利用文本分析进行因果推论,研究者还需要跳出具体的文本内容,在更加广阔的时空范围内考察研究对象的社会历史背景,发掘重大社会经济事件背后文本集合语义与主题分布的变化。韩剑等(2019)运用自然语言文本处理分析方法对数字贸易条款的异质性进行比较分析,在此基础上对各国签署数字贸易条款的影响因素进行实证检验。范梓腾(2021)用 LDA 主题模型对党委机关报进行建模,探究各省对数字政府建设的议题界定呈现出的特征差异及形成原因。覃飞等(2021)基于2009~2018年的国务院政府工作报告和企业年报文本数据,利用文本大数据分析技术测算企业年报和政府工作报告文本的政策相似度,并使用面板回归模型评估政策效果以及机制分析。
3.文本分析在政策中的发展趋势
政策文本研究正在经历定量化、大数据化和归因化的发展趋势(任弢等,2017)。结合文本分析的方法体系从4个方面论述其与政策研究结合的潜在路径。首先,“研究逻辑”维度需进一步发展结合文本的因果推论,拓展文本分析的研究深度。其次,“研究语料”维度需进一步发展对文本非结构化特征的分析,拓展文本分析的研究广度。此外,还需要收集更加高频的文本信息,并尝试将文本数据与多源、多模态的数据类型相结合,为实现更加广泛的高质量因果推论奠定基础。
上述4项趋势并不是孤立存在的。首先,“研究逻辑”的深化是进一步发展文本分析的核心,通过发展结合文本的因果推论,文本分析将进一步融入社会科学的主流方法论体系。其次,“研究语料”的丰富将进一步拓宽文本分析对象,从而为“研究逻辑”的深化提供更加多元的路径。最后,高频率文本数据收集与多源多模态信息融合是进一步深化“研究逻辑”的保障。通过采集更高频率文本构建纵贯性数据集,并融入更加丰富的情境与社会背景信息,将进一步提升基于文本的因果分析质量。
3.1 从描述性推论到因果推论
随着文本分析的发展,研究者不再满足开展简单的描述性推论,而越来越关注如何利用文本数据挖掘复杂社会现象背后的因果关系。这些研究可以横跨政府、市场乃至个人等不同层次。目前公共管理与公共政策领域的文本分析还是更多立足描述性推论,未来,本领域研究者应进一步考虑将非结构化语义提取与因果推论相结合,以提升文本分析在政策研究中的应用深度。
3.2 更多非结构化特征分析
在“研究语料”层面,文本分析需进一步向非结构化特征分析发展,从而进一步扩大文本分析的对象范围,拓展应用广度。越来越多的研究者尝试探究一些无法按固定规则直接从文本中提取的非结构化特征。对于非结构化语义的挖掘可以从词语、语句乃至篇章等不同层次开展,本质上是在标注样本、分词、实体识别等工作的基础上,结合多样化的统计和机器学习方法,对于信息进行加权处理。词语尺度的非结构化语义提取发展最为成熟,语句层面的非结构化语义提取相对而言更加复杂,篇章尺度的非结构化语义绝大多数情况下依赖机器学习技术的运用。
3.3 从低频文本信息到高频文本信息
要在更广阔的范畴下实现更高质量的因果推论,文本分析研究者还需要进一步优化数据收集策略,提升数据收集时频质量。传统情况下,政策研究所利用的文本数据往往来源于政策法规文本。受到制度约束和收集成本的限制,其采集频率往往以月或年为单位,存在较为明显的时滞性,研究者往往只能利用单截面、单时间序列或短面板数据进行分析。得益于数据技术的进步,目前社会科学研究者已可以采集更加高频的数据( Nakamura and Steinsson,2018) ,从而构建更长的时间序列或面板数据集合,更好地控制因果分析中的内生性等问题。
3.4 从单模分析到多源、多模态数据分析
提升数据来源的广泛性也是提升结合文本的因果推论质量的关键趋势。在大数据时代,研究者可以利用的数据类型大大丰富。除了文本数据,图像、音频、视频等数据类型逐渐得到挖掘。研究者可以进一步探索将文本数据与其他数据相融合,构建多源异构的数据集合进行分析,也可以拓展对于同一事物的多模态分析,从而更加深入地挖掘复杂因果关系。文本数据可以与传统数据相融合,弥补传统数据的不足之处。文本数据可以视作多媒体数据分解出的一个单模态。例如,视频数据本质上是音频、图像和文本的融合。研究者若能跳出单一模态,从整体上研究不同模态共生共现的状态,往往能够加深对于特定情境的理解。目前,多模态分析还属于社会科学中的前沿议题,仅有少数文献对此进行探索。研究者不仅可以研究对象“说”了什么、“做”了什么,还可以探索“说” 的方式、“做”的过程,尤其适用于对于微观决策情境的理解。
4. 小结
通过检索中外政策研究的重要学术期刊的相关文献,通过“研究语料—研究逻辑”的类型学分析框架对文本分析在政策研究领域的研究方法应用进行研究综述,发现文本分析目前在“内容特征”和“描述性推论”方面应用更加广泛,进一步分析得出文本分析从描述性推论到因果推论、更多非结构化分析、从低频文本到高频文本信息、从单模分析到多源、多模态数据分析的发展趋势。
本研究也存在一定局限性,对于文本分析在政策领域的文献检索还不够全面,应该更新文献检索方式,以获取全面文献;另外,对于研究及趋势的判断更多是主观观点,可以借助更加客观的知识挖掘进行综述。
1、凡本站及其子站注明“文章类型:原创”的所有作品,其版权属于山东国际商务网及其子站所有。其他媒体、网站或个人转载使用时必须注明:“文章来源:山东国际商务网”。
2、凡本站及其子站注明“文章类型:转载”、“文章类型:编译”、“文章类型:摘编”的所有作品,均转载、编译或摘编自其它媒体,转载、编译或摘编的目的在于传递更多信息,并不代表本站及其子站赞同其观点和对其真实性负责。其他媒体、网站或个人转载使用时必须保留本站注明的文章来源,并自负法律责任。